Det prøveudtagningsfejl eller prøvefejl I statistikker er det forskellen mellem gennemsnitsværdien af en prøve og middelværdien af den samlede befolkning. For at illustrere ideen, lad os forestille os, at den samlede befolkning i en by er en million mennesker, hvoraf den gennemsnitlige skostørrelse ønskes, for hvilken der udtages en tilfældig prøve på tusind mennesker.
Den gennemsnitlige størrelse, der fremgår af prøven, falder ikke nødvendigvis sammen med den samlede befolkning, selvom værdien skal være tæt, hvis prøven ikke er partisk. Denne forskel mellem gennemsnitsværdien af prøven og den for den samlede population er prøveudtagningsfejlen.
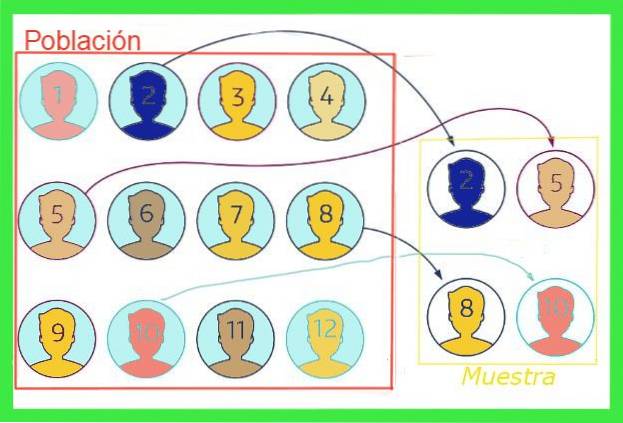
Generelt er middelværdien af den samlede befolkning ukendt, men der er teknikker til at reducere denne fejl og formler til at estimere prøveudtagningsfejlmargen der vil blive eksponeret i denne artikel.
Artikelindeks
Lad os sige, at du vil vide gennemsnitsværdien af en bestemt målbar egenskab x i en befolkning af størrelse N, men hvordan N er et stort antal, er det ikke muligt at gennemføre undersøgelsen af den samlede befolkning, så fortsætter vi med at tage en aleatory prøve af størrelse n<
Den gennemsnitlige værdi af prøven er angivet med
Antag, at de tager m prøver fra den samlede population N, alle i samme størrelse n med middelværdier
Disse middelværdier vil ikke være identiske med hinanden og vil alle være omkring befolkningens middelværdi μ. Det prøveudtagningsmargen E angiver den forventede adskillelse af middelværdierne
Det standard fejlmargen ε størrelse prøve n det er:
ε = σ / √n
hvor σ er standardafvigelsen (kvadratroden af variansen), der beregnes ved hjælp af følgende formel:
σ = √ [(x -
Betydningen af standard fejlmargen ε er følgende:
Det middelværdi
I det foregående afsnit blev formlen givet til at finde fejlinterval standard af en prøve af størrelse n, hvor ordet standard angiver, at det er en fejlmargin med 68% konfidens.
Dette indikerer, at hvis der blev taget mange prøver af samme størrelse n, 68% af dem giver gennemsnitlige værdier
Der er en simpel regel, kaldet regel 68-95-99.7 som giver os mulighed for at finde margenen på prøveudtagningsfejl E for tillidsniveauer på 68%, 95% Y 99,7% let, da denne margen er 1⋅ε, 2⋅ε og 3⋅ε henholdsvis.
Hvis han konfidensniveau γ ikke er noget af det ovenstående, så er prøveudtagningsfejlen standardafvigelsen σ ganget med faktoren Zy, som opnås ved hjælp af følgende procedure:
1.- Først signifikansniveau α som beregnes ud fra konfidensniveau γ ved hjælp af følgende forhold: α = 1 - γ
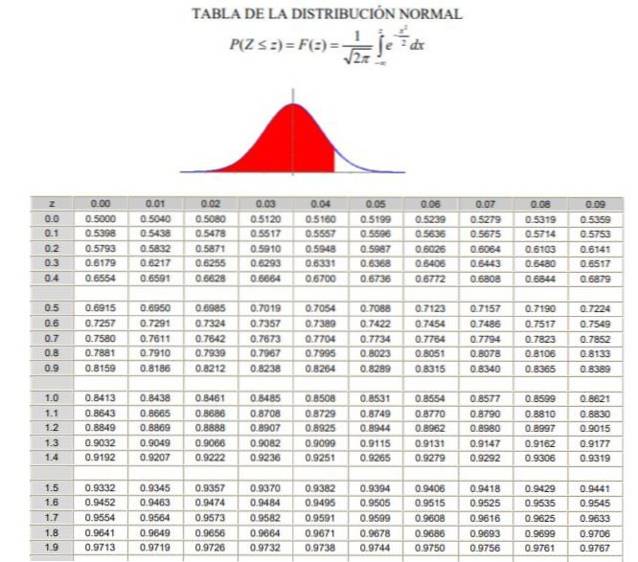
2. - Så skal du beregne værdien 1 - a / 2 = (1 + y) / 2, hvilket svarer til den akkumulerede normale frekvens mellem -∞ og Zy, i en normal eller standardiseret Gaussisk fordeling F (z), hvis definition kan ses i figur 2.
3.- Ligningen er løst F (Zy) = 1 - a / 2 ved hjælp af tabellerne for den normale fordeling (kumulativ) F, eller ved hjælp af et computerprogram, der har den omvendte standardiserede Gaussiske funktion F-1.
I sidstnævnte tilfælde har vi:
Zy = G-1(1 - α / 2).
4. - Endelig anvendes denne formel til prøveudtagningsfejl med et pålidelighedsniveau γ:
E = Zy⋅(σ / √n)
Beregn standard fejlmargen i gennemsnitsvægten af en prøve på 100 nyfødte. Beregningen af gennemsnitsvægten var
Det standard fejlmargen det er ε = σ / √n = (1.500 kg) / √100 = 0.15 kg. Hvilket betyder, at det med disse data kan udledes, at vægten af 68% af nyfødte er mellem 2.950 kg og 3.25 kg.
Bestemme margen for prøveudtagningsfejl E og vægtområdet på 100 nyfødte med et 95% konfidensniveau, hvis gennemsnitsvægten er 3.100 kg med standardafvigelse σ = 1.500 kg.
Hvis regel 68; 95; 99,7 → 1⋅ε; 2⋅ε; 3⋅ε, du har:
E = 2⋅ε = 2⋅0,15 kg = 0,30 kg
Det vil sige, at 95% af nyfødte har vægte mellem 2.800 kg og 3.400 kg.
Bestem vægteområdet for de nyfødte fra eksempel 1 med en konfidensmargen på 99,7%.
Samplingsfejlen med 99,7% konfidens er 3 σ / √n, som for vores eksempel er E = 3 * 0,15 kg = 0,45 kg. Herfra udledes det, at 99,7% af nyfødte vil have vægte mellem 2.650 kg og 3.550 kg.
Bestem faktoren Zy til et pålidelighedsniveau på 75%. Bestem marginen for prøveudtagningsfejl med dette niveau af pålidelighed for den sag, der er præsenteret i eksempel 1.
Det Selvtillidsniveau det er γ = 75% = 0,75, som er relateret til signifikansniveau a gennem forhold γ= (1 - a), så signifikansniveauet er a = 1 - 0,75 = 0,25.
Dette betyder, at den kumulative normale sandsynlighed mellem -∞ og Zy det er:
P (Z ≤ Zy ) = 1 - 0,125 = 0,875
Hvad svarer til en værdi Zy 1.1503, som vist i figur 3.
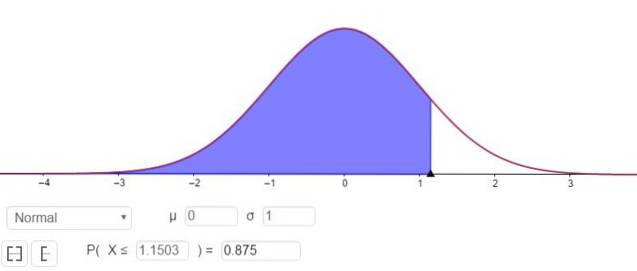
Det vil sige, at prøveudtagningsfejlen er E = Zy⋅(σ / √n)= 1.15⋅(σ / √n).
Når de anvendes på dataene fra eksempel 1, giver det en fejl på:
E = 1,15 * 0,15 kg = 0,17 kg
Med et konfidensniveau på 75%.
Hvad er konfidensniveauet, hvis Zα / 2 = 2,4 ?
P (Z ≤ Zα / 2 ) = 1 - a / 2
P (Z ≤ 2,4) = 1 - α / 2 = 0,9918 → α / 2 = 1 - 0,9918 = 0,0082 → α = 0,0164
Betydningsniveauet er:
α = 0,0164 = 1,64%
Og endelig forbliver tillidsniveauet:
1- α = 1 - 0,0164 = 100% - 1,64% = 98,36%



Endnu ingen kommentarer