Det grader af frihed i statistik er de antallet af uafhængige komponenter i en tilfældig vektor. Hvis vektoren har n komponenter, og der er s lineære ligninger, der relaterer deres komponenter, så grad af frihed er n-p.
Begrebet grader af frihed Det vises også i teoretisk mekanik, hvor de stort set svarer til dimensionen af rummet, hvor partiklen bevæger sig minus antallet af bindinger..
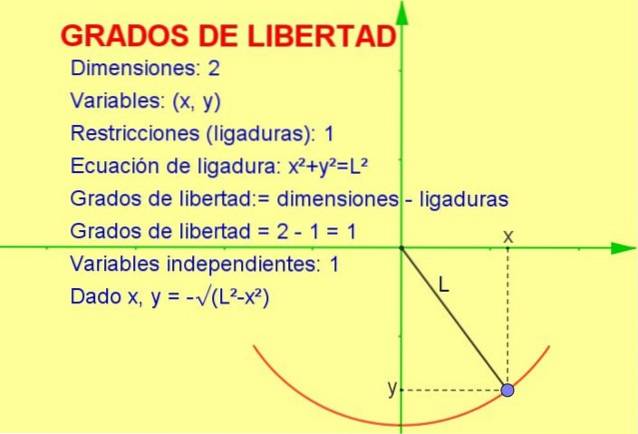
Denne artikel vil diskutere begrebet frihedsgrader anvendt på statistik, men et mekanisk eksempel er lettere at visualisere i geometrisk form.
Artikelindeks
Afhængigt af den sammenhæng, hvori det anvendes, kan måden at beregne antallet af frihedsgrader variere på, men den underliggende idé er altid den samme: samlede dimensioner minus antal begrænsninger.
Lad os overveje en oscillerende partikel bundet til en streng (et pendul), der bevæger sig i det lodrette x-y-plan (2 dimensioner). Imidlertid er partiklen tvunget til at bevæge sig på radiusens omkreds lig med akkordlængden.
Da partiklen kun kan bevæge sig på denne kurve, er antallet af grader af frihed er 1. Dette kan ses i figur 1.
Måden at beregne antallet af frihedsgrader på er at tage forskellen i antallet af dimensioner minus antallet af begrænsninger:
frihedsgrader: = 2 (dimensioner) - 1 (ligatur) = 1
En anden forklaring, der giver os mulighed for at nå frem til resultatet, er følgende:
-Vi ved, at positionen i to dimensioner er repræsenteret af et punkt med koordinater (x, y).
-Men da punktet skal tilfredsstille ligningen af omkredsen (xto + Yto = Lto) for en given værdi af variablen x bestemmes variablen y af ligningen eller begrænsningen.
Således er kun en af variablerne uafhængige, og systemet har en (1) grad af frihed.
Antag vektoren for at illustrere, hvad begrebet betyder
x = (x1, xto,..., xn)
Hvad repræsenterer prøven af n normalt distribuerede tilfældige værdier. I dette tilfælde den tilfældige vektor x har n uafhængige komponenter og derfor siges det at x har n grader af frihed.
Lad os nu bygge vektoren r affald
r = (x1 -
Hvor
Så summen
(x1 -
Det er en ligning, der repræsenterer en begrænsning (eller binding) på elementerne i vektoren r af resterne, da hvis n-1-komponenter i vektoren er kendt r, begrænsningsligningen bestemmer den ukendte komponent.
Derfor vektoren r af dimension n med begrænsningen:
∑ (xjeg -
Har (n - 1) frihedsgrader.
Igen anvendes det, at beregningen af antallet af frihedsgrader er:
frihedsgrader: = n (dimensioner) - 1 (begrænsninger) = n-1
Variansen sto er defineret som gennemsnittet af kvadratet af afvigelser (eller rester) af stikprøven af n-data:
sto = (r•r) / (n-1)
hvor r er vektoren for resterne r = (x1 -
sto = ∑ (xjeg -
Under alle omstændigheder skal det bemærkes, at når man beregner middelværdien af residualernes kvadrat, divideres det med (n-1) og ikke med n, da som beskrevet i det foregående afsnit, antallet af frihedsgrader for vektor r er (n-1).
Hvis til beregningen af variansen blev divideret med n i stedet for (n-1) ville resultatet have en bias, der er meget signifikant for værdier på n under 50 år.
I litteraturen vises variansformlen også med divisoren n i stedet for (n-1), når det kommer til variationen i en population.
Men sættet med den tilfældige variabel for restprodukterne, repræsenteret af vektoren r, Selvom den har dimension n, har den kun (n-1) frihedsgrader. Men hvis antallet af data er stort nok (n> 500), konvergerer begge formler til det samme resultat.
Regnemaskiner og regneark giver begge versioner af variansen og standardafvigelsen (som er kvadratroden af variansen).
Vores anbefaling i betragtning af den analyse, der præsenteres her, er at altid vælge versionen med (n-1) hver gang det er nødvendigt at beregne variansen eller standardafvigelsen for at undgå partiske resultater..
Nogle sandsynlighedsfordelinger i kontinuerlig tilfældig variabel afhænger af en kaldet parameter grad af frihed, er tilfældet med Chi-kvadratfordelingen (χto).
Navnet på denne parameter kommer nøjagtigt fra frihedsgraderne for den underliggende tilfældige vektor, som denne fordeling gælder for.
Antag, at vi har g-populationer, hvorfra der tages prøver af størrelse n:
x1 = (x11, x1to,… X1n)
X2 = (x21, x2to,... X2n)
... .
xj = (xj1, xjto,... Xjn)
... .
Xg = (xg1, xgto,... Xgn)
En befolkning j hvad har gennemsnit
Den standardiserede eller normaliserede variabel zjjeg er defineret som:
zjjeg = (xjjeg -
Og vektoren Zj er defineret således:
Zj = (zj1, zjto,..., zjjeg,..., zjn) og følger den standardiserede normalfordeling N (0,1).
Så variablen:
Spørgsmål = ((z11 ^ 2 + z21^ 2 +…. + zg1^ 2),…., (Z1n^ 2 + z2n^ 2 +…. + zgn^ 2))
følg fordelingen χto(g) kaldte chi kvadratfordeling med grad af frihed g.
Når du vil teste hypoteser baseret på et bestemt sæt tilfældige data, skal du kende antal frihedsgrader g for at kunne anvende Chi kvadrat testen.
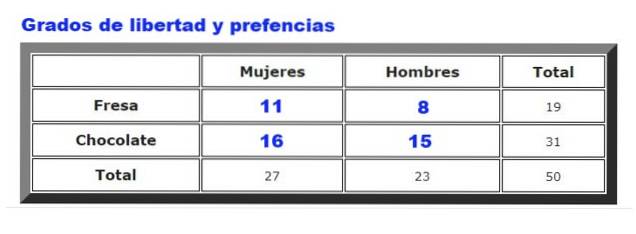
Som et eksempel analyseres de data, der er indsamlet om præferencer for chokolade eller jordbæris blandt mænd og kvinder i en bestemt isbar. Hyppigheden, hvormed mænd og kvinder vælger jordbær eller chokolade, er opsummeret i figur 2.
For det første beregnes tabellen over forventede frekvenser, som udarbejdes ved at multiplicere samlede rækker For ham samlede kolonner, divideret med samlede data. Resultatet er vist i følgende figur:

Derefter fortsætter vi med at beregne Chi-firkanten (ud fra dataene) ved hjælp af følgende formel:
χto = ∑ (F.eller - Fog)to / Fog
Hvor Feller er de observerede frekvenser (figur 2) og Fog er de forventede frekvenser (figur 3). Summationen går over alle rækker og kolonner, som i vores eksempel giver fire termer.
Efter at have udført operationerne får du:
χto = 0,2043.
Nu er det nødvendigt at sammenligne med den teoretiske Chi-firkant, som afhænger af antal frihedsgrader g.
I vores tilfælde bestemmes dette antal som følger:
g = (# rækker - 1) (# kolonner - 1) = (2 - 1) (2 - 1) = 1 * 1 = 1.
Det viser sig, at antallet af frihedsgrader g i dette eksempel er 1.
Hvis du vil kontrollere eller afvise nulhypotesen (H0: der er ingen sammenhæng mellem TASTE og KØN) med et signifikansniveau på 1%, beregnes den teoretiske Chi-kvadratværdi med frihedsgraden g = 1.
Værdien søges, der gør den akkumulerede frekvens (1 - 0.01) = 0.99, det vil sige 99%. Denne værdi (som kan opnås fra tabellerne) er 6.636.
Da den teoretiske Chi overstiger den beregnede, bekræftes nulhypotesen.
Det vil sige med de indsamlede data, Ikke observeret forholdet mellem variablerne TASTE og Køn.



Endnu ingen kommentarer