Den statistiske frekvens henviser til gentagelse af en begivenhed eller begivenhed, mens relativ hyppighed henviser til sammenligning; det vil sige at tale om relativ hyppighed er at fastslå, hvor meget en begivenhed gentages i forhold til det samlede antal mulige begivenheder.
For eksempel antallet af børn i en bestemt alder i forhold til det samlede antal børn i en skole, eller hvor mange sportsvogne der er blandt alle køretøjerne på en parkeringsplads.
I sammenhæng med datahåndtering er det undertiden praktisk at klassificere dem efter nogle karakteristika, for eksempel kan befolkningstællingsdata grupperes efter aldersgrupper, indkomstniveau, uddannelsesniveau osv..
Disse grupperinger kaldes klasser, og mængden af elementer, der svarer til hver klasse kaldes klassen eller absolut frekvens. Når frekvensen divideres med det samlede antal data, opnås alikvoten.
Alikvoten repræsenterer denne klasse i forhold til det samlede antal og er kendt som den relative frekvens, som udtrykkes som en størrelse mellem nul og en eller ganget med hundrede og udtrykkes som en procentdel af det samlede antal..
For eksempel, hvis du har 20 7-årige børn i haven på en skole, hvor der er 100 børn; den relative frekvens ville være 20/100 = 0,2 eller 20%.
Relativ frekvens er et af de elementer, der udgør en frekvensfordelingstabel. Disse tabeller præsenterer informationen indeholdt i en gruppe af data, sorteret efter klasser, i forhold til en bestemt egenskab..
For konstruktionen skal følgende defineres: antallet af klasser, deres grænser (som skal være klare og eksklusive), klassens repræsentative værdi og frekvenser.
Amplitude af variation: Forskellen mellem det største og det mindste af tallene.
Antal klasser: antal klasser, blandt hvilke vi distribuerer numrene. Det er normalt mellem 5 og 20.
Klasseinterval: række værdier, der definerer en klasse. Dens ekstremer kaldes de nedre og øvre grænser.
Klassemærke (xi): midtpunkt for klasseintervallet eller repræsentativ værdi for klassen. I teorien antages det, at alle værdier i en klasse svarer til dette tal.
Vi skal bygge en frekvensfordelingstabel, som et eksempel, og med den illustrerer vi, hvordan den relative frekvens beregnes.
Vi tager følgende casestudie fra Canavos, 1998:
Du vil vide den ugentlige løn for P & R-virksomhedens ansatte, udtrykt i U.S. $. Til dette vælges en repræsentativ prøve på 65 ansatte.
Følgende resultater opnås: 251 252,5 314,1 263305319,5 265 267,8 304 306,35 262 250 308 302,75 256 258 267 277,55 281,35 255,5 253 259 263 266,75 278 295 296 299,5 263,5 261 260,25 277 272,5 271 286 292 272 286 272 272 286 279275277279276,75 281 287 286,5 294,25 285 288 296 283,25 281,5 293 284 282 292 299 286 283
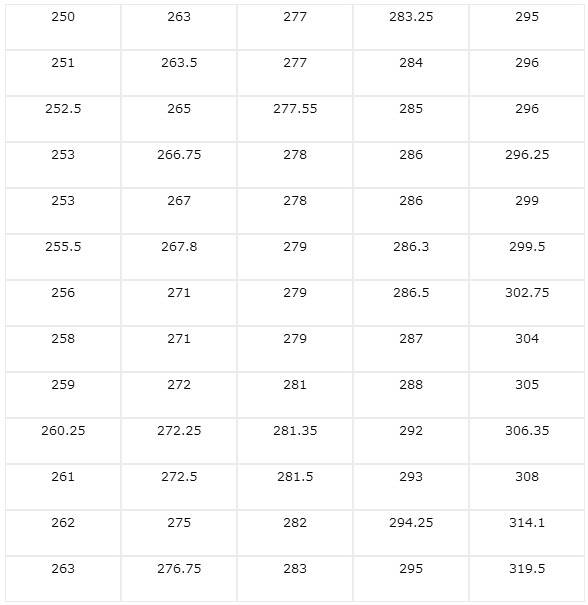
Antallet af klasser vælges i betragtning af, at der er få klasser, og delerne af amplitude af variation er næsten 70.
7 klasser er et behageligt antal klasser at håndtere, og klasseintervallerne ville være 10, hvilket er et ideelt antal til at arbejde med grupperede data.
- Klasseinterval (Ic), der repræsenterer klassen (klasseinterval), i dette tilfælde de nedre og øvre grænser for den løn, der er inkluderet i klassen.
- Klassecenter (xi), som repræsenterer værdien af den gennemsnitlige klasseløn.
- Absolut frekvens (fi), som repræsenterer den absolutte frekvens, i dette tilfælde det lønbeløb, der tilhører klassen.
- Relativ frekvens (hi), er kvotienten mellem den absolutte frekvens (fi) og det samlede antal data (n), udtrykt i procent.
- Kumulativ absolut frekvens (Fi) angiver, hvor mange elementer i datalisten, der er mindre end eller lig med den øvre grænse for en bestemt klasse. Det er summen af de absolutte frekvenser fra første klasse til den valgte klasse.
- Kumulativ relativ frekvens (Hej) er kvotienten mellem den akkumulerede absolutte frekvens (Fi) og det samlede antal data (n), udtrykt i procent.
Tabellen er:
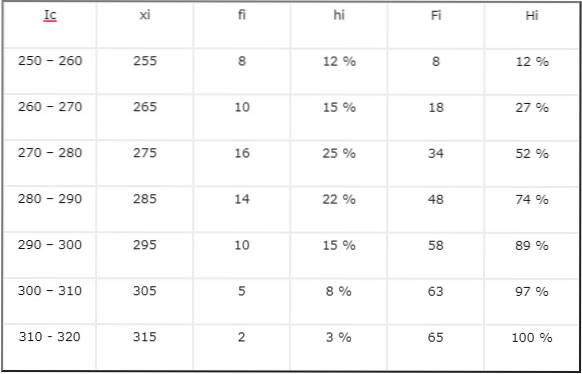
Det skal bemærkes, at den relative frekvens kan være absolut eller akkumuleret, og begrebet relativ frekvens placerer os i en sammenhæng med sammenligning med en total. Enhver mængde kan beregnes ved hjælp af denne type indeks.
For eksempel, når vi taler om procentdelen af studerende, der har bestået en bestemt prøve eller eksamen, er denne procentdel andelen af det samlede antal studerende, der har bestået testen eller eksamen; det vil sige, det er et beløb i forhold til det samlede antal studerende.
Endnu ingen kommentarer