Det målinger af central tendens, spredning og position, er værdier, der bruges til korrekt fortolkning af et sæt statistiske data. Disse kan bearbejdes direkte, da de fås fra den statistiske undersøgelse, eller de kan organiseres i grupper med lige frekvens, hvilket letter analysen..
De giver mulighed for at vide, hvilke værdier de statistiske data er grupperet.
Det er også kendt som gennemsnittet af værdierne for en variabel og opnås ved at tilføje alle værdierne og dividere resultatet med det samlede antal data.
Lad være en variabel x, som vi har n data uden at organisere eller gruppere, dens aritmetiske gennemsnit beregnes som følger:
Og sammenfattende notation:
Ejerne af en bjergturistkrog har til hensigt at vide, hvor mange dage de besøgende i gennemsnit forbliver i faciliteterne. Til dette blev der ført en oversigt over de dage, hvor 20 grupper af turister varede, og opnåede følgende data:
1; 1; to; to; 1; 4; 5; 1; 3; 4; 5; 4; 3; 1; 1; to; to; 3; 4; 1
Det gennemsnitlige antal dage, som turister overnatter, er:
Hvis dataene for variablen er organiseret i en tabel over absolutte frekvenser fjeg og klassecentrene er x1, xto,..., xn, middelværdien beregnes ved:
Sammenfattende notation:
Medianen for en gruppe af n-værdier for variablen x er gruppens centrale værdi, forudsat at værdierne er ordnet i stigende rækkefølge. På denne måde er halvdelen af alle værdier mindre end tilstanden, og den anden halvdel er større..
Følgende tilfælde kan forekomme:
-Antal n af værdierne for variablen x ulige: medianen er den værdi, der er lige midt i gruppen af værdier:
-Antal n af værdierne for variablen x par: i dette tilfælde beregnes medianen som gennemsnittet af de to centrale værdier i datagruppen:
For at finde medianen for dataene fra turisthostellet bestilles de først fra laveste til højeste:
1; 1; 1; 1; 1; 1; 1; to; to; to; to; 3; 3; 3; 4; 4; 4; 4; 5; 5
Antallet af data er lige, derfor er der to centrale data: X10 og Xelleve og da begge er værd 2, er deres gennemsnit også.
Median = 2
Følgende formel anvendes:
Symbolerne i formlen betyder:
-c: bredde på intervallet, der indeholder medianen
-BM: nedre grænse for det samme interval
-Fm: antal observationer indeholdt i det interval, som medianen hører til.
-n: samlede data.
-FBM: antal observationer Før af intervallet, der indeholder medianen.
Tilstanden for ikke-grupperede data er den værdi med den højeste frekvens, mens den for grupperede data er den klasse med den højeste frekvens. Mode betragtes som den mest repræsentative data eller klasse for distributionen.
To vigtige egenskaber ved denne foranstaltning er, at et datasæt kan have mere end en tilstand, og tilstanden kan bestemmes for både kvantitative og kvalitative data..
Fortsat med dataene fra turistparadoren er den, der gentages mest, 1, derfor er den mest almindelige ting, at turister bliver 1 dag i paradoren.
Målinger af spredning beskriver, hvor klyngede data er omkring de centrale mål.
Det beregnes ved at trække de største data og de mindste data. Hvis denne forskel er stor, er det et tegn på, at dataene er spredt, mens små værdier indikerer, at dataene er tæt på gennemsnittet..
Området for data fra turistparador er:
Område = 5−1 = 4
For at finde variansen sto Det er nødvendigt først at kende det aritmetiske gennemsnit, derefter den kvadratiske forskel mellem hvert stykke data og gennemsnittet beregnes, alle tilføjes og divideres med det samlede antal observationer. Disse forskelle er kendt som afvigelser.
Variansen, som altid er positiv (eller nul), angiver, hvor langt observationerne er fra gennemsnittet: hvis variansen er høj, er værdierne mere spredte, end når variansen er lille.
Variationen for data fra turisthostel er:
1; 1; to; to; 1; 4; 5; 1; 3; 4; 5; 4; 3; 1; 1; to; to; 3; 4; 1
For at finde variansen af et grupperet datasæt kræves følgende: i) middelværdien, ii) frekvensen fjeg som er de samlede data i hver klasse og iii) xjeg eller klasse værdi:
Standardafvigelsen er den positive kvadratrod af variansen, så den har en fordel i forhold til variansen: den kommer i de samme enheder som variablen, der undersøges, og du har således en mere direkte idé om, hvor tæt eller langt variablen er fra gennemsnittet.
Det bestemmes simpelthen ved at finde kvadratroden af variansen for ikke-grupperede data:
Standardafvigelsen for data fra turisthostel er:
s = √ (sto) = √1.95 = 1.40
Det beregnes ved at finde kvadratroden af variansen for grupperede data:
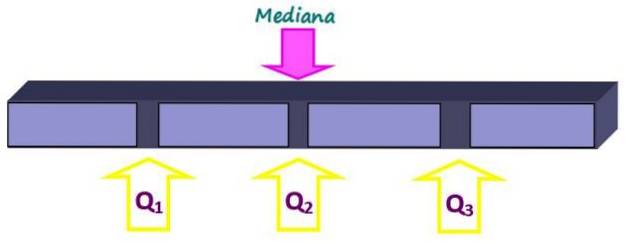
Måling af position opdeler et ordnet datasæt i stykker af samme størrelse. Medianen, ud over at være et mål for central tendens, er også et mål for position, da den deler helheden i to lige store dele. Men mindre dele kan opnås med kvartiler, deciler og percentiler.
Kvartilerne opdeler sættet i fire lige store dele, der hver indeholder 25% af dataene. De betegnes som Q1, Spørgsmålto og Q3 og medianen er kvartilen Qto. På denne måde er 25% af dataene under Q-kvartilen.1, 50% under Q-kvartilento eller median og 75% under Q-kvartilen3.
Dataene bestilles, og summen er opdelt i 4 grupper med det samme antal data hver. Positionen for det første kvartil findes af:
Spørgsmål1 = (n + 1) / 4
Hvor n er de samlede data. Hvis resultatet er et heltal, lokaliseres de data, der svarer til denne position, men hvis det er decimal, beregnes dataene svarende til heltalets gennemsnit med det næste, eller for større præcision interpoleres det lineært mellem dataene.
Positionen for det første kvartil Q1 for data fra turist parador er:
Spørgsmål1 = (n + 1) / 4 = (20 + 1) / 4 = 5,25
Dette er positionen for kvartil 1, og da resultatet er decimal, søges data X5 og X6, som henholdsvis er X5 = 1 og X6 = 1 og er gennemsnit, hvilket resulterer i:
Første kvartil = 1
1; 1; 1; 1; 1; 1; 1; to; to; to; to; 3; 3; 3; 4; 4; 4; 4; 5; 5.
Positionen for det andet kvartil Qto det er:
Spørgsmålto = 2 (n + 1) / 4 = 10,5
Hvad er gennemsnittet mellem X10 og Xelleve og matcher medianen:
Andet kvartil = Median = 2
Placeringen af det tredje kvartil beregnes af:
Spørgsmål3 = 3 (n + 1) / 4 = 3 (20 + 1) / 4 = 15,75
Det er også decimal, og derfor beregnes X i gennemsnitfemten og X16:
1; 1; 1; 1; 1; 1; 1; to; to; to; to; 3; 3; 3; 4; 4; 4; 4; 5; 5.
Men da begge er værd 4:
Tredje kvartil = 4
Den generelle formel for placering af kvartiler i ikke-grupperede data er:
Spørgsmålk = k (n + 1) / 4
Med k = 1,2,3.
De beregnes på samme måde som medianen:

Forklaringen på symbolerne er:
-BSpørgsmål: nedre grænse for intervallet, der indeholder kvartilen
-c: bredden af dette interval
-Fhvad: antal observationer indeholdt i kvartilintervallet.
-n: samlede data.
-FBQ: antal data Før af intervallet, der indeholder kvartilen.
Deciler og percentiler opdeler datasættet i henholdsvis 10 lige store dele og 100 lige store dele, og deres beregning udføres på samme måde som kvartilernes.
Formlerne anvendes henholdsvis:
Dk = k (n + 1) / 10
Med k = 1,2,3… 9.
Decile D5 skal være lig medianen.
Pk = k (n + 1) / 100
Med k = 1,2,3… 99.
P-percentilenhalvtreds skal være lig medianen.
I eksemplet med turisthostel, D's position3 det er:
D3 = 3 (20 + 1) / 10 = 6,3
Da det er et decimaltal, beregnes X i gennemsnit6 og X7, begge er lig med 1:
1; 1; 1; 1; 1; 1; 1; to; to; to; to; 3; 3; 3; 4; 4; 4; 4; 5; 5
Det betyder, at 3 tiendedele af dataene er under X7 = 1 og de resterende ovenfor.
Formlerne er analoge med dem for kvartiler. D bruges til at betegne deciler og P for percentiler, og symbolerne fortolkes ens:
Når dataene er symmetrisk fordelt, og fordelingen er unimodal, kaldes der en regel empirisk regel eller regel 68 - 95 - 99, der grupperer dem i følgende intervaller:
I hvilket interval er 95% af dataene fra turistparadoren?
De er i intervallet: [2.5−1.40; 2,5 + 1,40] = [1,1; 3.9].



Endnu ingen kommentarer